与常规顺序集合库一样,Scala 的并行集合库包含大量集合操作,这些操作在许多不同的并行集合实现中统一存在。与顺序集合库一样,Scala 的并行集合库力求通过同样以并行集合“模板”实现大多数操作来防止代码重复,而这些模板只需定义一次,即可被许多不同的并行集合实现灵活继承。
此方法的好处大大简化了维护和可扩展性。在维护方面——通过让所有并行集合继承并行集合操作的单一实现,维护变得更加容易和稳健;错误修复会向下传播到类层次结构,而不需要重复实现。出于同样的原因,整个库变得更容易扩展——新的集合类可以简单地继承它们的大多数操作。
核心抽象
上述的“模板”特征在两个核心抽象(Splitter 和 Combiner)方面实现了大多数并行操作。
Splitter
顾名思义,Splitter 的工作是将并行集合拆分为其元素的非平凡分区。基本思想是将集合拆分为更小的部分,直到它们小到足以顺序操作。
trait Splitter[T] extends Iterator[T] {
def split: Seq[Splitter[T]]
}
有趣的是,Splitter 是作为 Iterator 实现的,这意味着除了拆分之外,框架还使用它们来遍历并行集合(即,它们继承了 Iterator 上的标准方法,例如 next 和 hasNext)。这种“拆分迭代器”的独特之处在于,它的 split 方法进一步将 this(同样是 Splitter,一种 Iterator 类型)拆分为其他 Splitter,每个 Splitter 都遍历整个并行集合中元素的不相交子集。与普通 Iterator 类似,在调用 Splitter 的 split 方法后,该 Splitter 将失效。
通常,集合使用 Splitter 分区为大致相同大小的子集。在需要更多任意大小分区的场合,尤其是在并行序列中,会使用 PreciseSplitter,它继承了 Splitter,此外还实现了精确拆分方法 psplit。
Combiner
可以将 Combiner 视为 Scala 顺序集合库中的泛化 Builder。每个并行集合提供一个单独的 Combiner,就像每个顺序集合提供一个 Builder 一样。
在顺序集合的情况下,元素可以添加到 Builder 中,并且可以通过调用 result 方法来生成一个集合,在并行集合的情况下,Combiner 有一个名为 combine 的方法,该方法采用另一个 Combiner 并生成一个新的 Combiner,其中包含两个元素的并集。调用 combine 后,两个 Combiner 都会失效。
trait Combiner[Elem, To] extends Builder[Elem, To] {
def combine(other: Combiner[Elem, To]): Combiner[Elem, To]
}
上面的两个类型参数 Elem 和 To 分别表示元素类型和结果集合的类型。
注意:给定两个 Combiner,c1 和 c2,其中 c1 eq c2 为 true(表示它们是同一个 Combiner),调用 c1.combine(c2) 始终不执行任何操作,只会返回接收 Combiner,c1。
层次结构
Scala 的并行集合在很大程度上借鉴了 Scala(顺序)集合库的设计——事实上,它反映了常规集合框架的对应特征,如下所示。
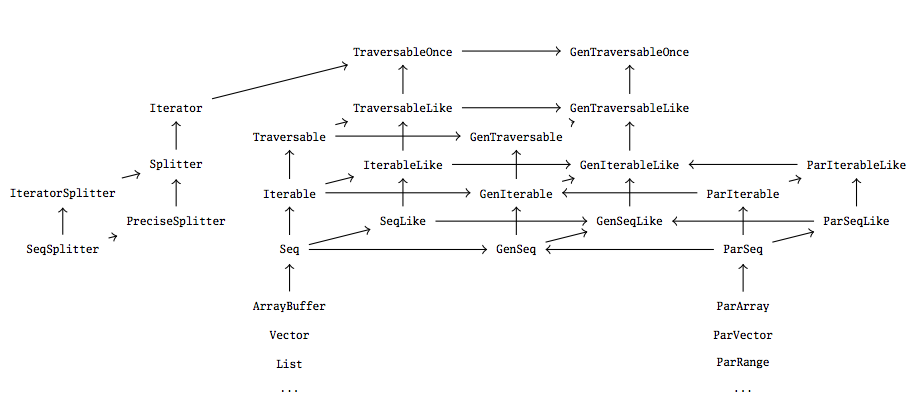
目标当然是尽可能紧密地将并行集合与顺序集合集成在一起,以便直接替换顺序集合和并行集合。
为了能够引用一个可能是顺序或并行集合的集合(这样可以通过分别调用 par 和 seq 来在并行集合和顺序集合之间“切换”),必须存在两种集合类型的公共超类型。这就是上面显示的“通用”特征的由来,GenTraversable、GenIterable、GenSeq、GenMap 和 GenSet,它们不保证按顺序或一次遍历一个元素。相应的顺序或并行特征继承自这些特征。例如,ParSeq 和 Seq 都是通用序列 GenSeq 的子类型,但它们在继承关系上彼此无关。
有关顺序集合和并行集合之间共享的层次结构的更详细讨论,请参阅技术报告。 [1]