Martin Odersky、Lex Spoon 和 Julien Richard-Foy
本文展示了如何在集合框架之上实现自定义集合类型。建议先阅读有关 集合架构 的文章。
如果你想集成一个新的集合类,需要做什么,以便它可以从具有正确类型的预定义操作中获益?在接下来的几节中,你将了解三个执行此操作的示例,即使用 Patricia 树实现的受限序列、RNA 碱基序列和前缀映射。
受限序列
假设你想要创建一个不可变集合,其中最多包含 n 个元素:如果添加更多元素,则会删除第一个元素。
第一个任务是找到集合的超类型:是 Seq、Set、Map 还是 Iterable?在我们的例子中,很容易选择 Seq,因为我们的集合可以包含重复项,并且迭代顺序由插入顺序决定。但是,Seq 的一些属性 不满足
(xs ++ ys).size == xs.size + ys.size
因此,作为基本集合类型的唯一明智选择是 collection.immutable.Iterable。
Capped 类的第一个版本
import scala.collection._
class Capped1[A] private (val capacity: Int, val length: Int, offset: Int, elems: Array[Any])
extends immutable.Iterable[A] { self =>
def this(capacity: Int) =
this(capacity, length = 0, offset = 0, elems = Array.ofDim(capacity))
def appended[B >: A](elem: B): Capped1[B] = {
val newElems = Array.ofDim[Any](capacity)
Array.copy(elems, 0, newElems, 0, capacity)
val (newOffset, newLength) =
if (length == capacity) {
newElems(offset) = elem
((offset + 1) % capacity, length)
} else {
newElems(length) = elem
(offset, length + 1)
}
new Capped1[B](capacity, newLength, newOffset, newElems)
}
@`inline` def :+ [B >: A](elem: B): Capped1[B] = appended(elem)
def apply(i: Int): A = elems((i + offset) % capacity).asInstanceOf[A]
def iterator: Iterator[A] = new AbstractIterator[A] {
private var current = 0
def hasNext = current < self.length
def next(): A = {
val elem = self(current)
current += 1
elem
}
}
override def className = "Capped1"
}
import scala.collection.*
class Capped1[A] private (val capacity: Int, val length: Int, offset: Int, elems: Array[Any])
extends immutable.Iterable[A]:
self =>
def this(capacity: Int) =
this(capacity, length = 0, offset = 0, elems = Array.ofDim(capacity))
def appended[B >: A](elem: B): Capped1[B] =
val newElems = Array.ofDim[Any](capacity)
Array.copy(elems, 0, newElems, 0, capacity)
val (newOffset, newLength) =
if length == capacity then
newElems(offset) = elem
((offset + 1) % capacity, length)
else
newElems(length) = elem
(offset, length + 1)
Capped1[B](capacity, newLength, newOffset, newElems)
end appended
inline def :+ [B >: A](elem: B): Capped1[B] = appended(elem)
def apply(i: Int): A = elems((i + offset) % capacity).asInstanceOf[A]
def iterator: Iterator[A] = new AbstractIterator[A]:
private var current = 0
def hasNext = current < self.length
def next(): A =
val elem = self(current)
current += 1
elem
end iterator
override def className = "Capped1"
end Capped1
上面的清单展示了我们有上限的集合实现的第一个版本。它将在稍后进行优化。类 Capped1 有一个私有构造函数,它以集合容量、长度、偏移量(第一个元素索引)和基础数组作为参数。公共构造函数仅获取集合的容量。它将长度和偏移量设置为 0,并使用一个空元素数组。
appended 方法定义了如何将元素追加到给定的 Capped1 集合:它创建一个新的基础元素数组,复制当前元素并添加新元素。只要元素数量不超过 容量,新元素就会追加到之前的元素之后。但是,一旦达到最大容量,新元素就会替换集合的第一个元素(在 偏移量 索引处)。
apply 方法实现了索引访问:它通过添加 偏移量 将给定的索引转换为基础数组中的对应索引。
这两个方法 appended 和 apply 实现了 Capped1 集合类型的特定行为。除了它们,我们还必须实现 iterator,以使通用集合操作(例如 foldLeft、count 等)在 Capped1 集合上运行。我们在此通过使用索引访问来实现它。
最后,我们重写 className 以返回集合的名称 “Capped1”。此名称由 toString 操作使用。
以下是与 Capped1 集合的一些交互
scala> val c0 = new Capped1(capacity = 4)
val c0: Capped1[Nothing] = Capped1()
scala> val c1 = c0 :+ 1 :+ 2 :+ 3
val c1: Capped1[Int] = Capped1(1, 2, 3)
scala> c1.length
val res2: Int = 3
scala> c1.lastOption
val res3: Option[Int] = Some(3)
scala> val c2 = c1 :+ 4 :+ 5 :+ 6
val c2: Capped1[Int] = Capped1(3, 4, 5, 6)
scala> val c3 = c2.take(3)
val c3: collection.immutable.Iterable[Int] = List(3, 4, 5)
您可以看到,如果我们尝试使用超过四个元素来增加集合,则会删除第一个元素(参见 res4)。除了最后一个操作之外,其他操作的行为符合预期:在调用 take 之后,我们得到一个 List,而不是预期的 Capped1 集合。这是因为在 类 Capped1 中所做的所有操作都是使 Capped1 扩展 immutable.Iterable。此类有一个 take 方法,该方法返回一个 immutable.Iterable,并且该方法是根据 immutable.Iterable 的默认实现 List 实现的。因此,这就是您在上一次交互的最后一行中所看到的。
现在您已经理解了事物为何会以这种方式存在,那么下一个问题应该是需要做什么来改变它们?一种方法是在类 Capped1 中覆盖 take 方法,也许像这样
def take(count: Int): Capped1 = …
这将为 take 完成这项工作。但是 drop、filter 或 init 怎么样?事实上,集合中有超过五十个方法可以再次返回一个集合。为了保持一致性,所有这些方法都必须被覆盖。这看起来越来越不像一个有吸引力的选择。幸运的是,有一种更容易的方法可以达到相同的效果,如下一节所示。
Capped 类的第二个版本
import scala.collection._
class Capped2[A] private (val capacity: Int, val length: Int, offset: Int, elems: Array[Any])
extends immutable.Iterable[A]
with IterableOps[A, Capped2, Capped2[A]] { self =>
def this(capacity: Int) = // as before
def appended[B >: A](elem: B): Capped2[B] = // as before
@`inline` def :+ [B >: A](elem: B): Capped2[B] = // as before
def apply(i: Int): A = // as before
def iterator: Iterator[A] = // as before
override def className = "Capped2"
override val iterableFactory: IterableFactory[Capped2] = new Capped2Factory(capacity)
override protected def fromSpecific(coll: IterableOnce[A]): Capped2[A] = iterableFactory.from(coll)
override protected def newSpecificBuilder: mutable.Builder[A, Capped2[A]] = iterableFactory.newBuilder
override def empty: Capped2[A] = iterableFactory.empty
}
class Capped2Factory(capacity: Int) extends IterableFactory[Capped2] {
def from[A](source: IterableOnce[A]): Capped2[A] =
(newBuilder[A] ++= source).result()
def empty[A]: Capped2[A] = new Capped2[A](capacity)
def newBuilder[A]: mutable.Builder[A, Capped2[A]] =
new mutable.ImmutableBuilder[A, Capped2[A]](empty) {
def addOne(elem: A): this.type = { elems = elems :+ elem; this }
}
}
class Capped2[A] private(val capacity: Int, val length: Int, offset: Int, elems: Array[Any])
extends immutable.Iterable[A],
IterableOps[A, Capped2, Capped2[A]]:
self =>
def this(capacity: Int) = // as before
def appended[B >: A](elem: B): Capped2[B] = // as before
inline def :+[B >: A](elem: B): Capped2[B] = // as before
def apply(i: Int): A = // as before
def iterator: Iterator[A] = // as before
override def className = "Capped2"
override val iterableFactory: IterableFactory[Capped2] = Capped2Factory(capacity)
override protected def fromSpecific(coll: IterableOnce[A]): Capped2[A] = iterableFactory.from(coll)
override protected def newSpecificBuilder: mutable.Builder[A, Capped2[A]] = iterableFactory.newBuilder
override def empty: Capped2[A] = iterableFactory.empty
end Capped2
class Capped2Factory(capacity: Int) extends IterableFactory[Capped2]:
def from[A](source: IterableOnce[A]): Capped2[A] =
(newBuilder[A] ++= source).result()
def empty[A]: Capped2[A] = Capped2[A](capacity)
def newBuilder[A]: mutable.Builder[A, Capped2[A]] =
new mutable.ImmutableBuilder[A, Capped2[A]](empty):
def addOne(elem: A): this.type =
elems = elems :+ elem; this
end Capped2Factory
Capped 类不仅需要从 Iterable 继承,还需要从其实现特征 IterableOps 继承。这在类 Capped2 的上述列表中显示。新实现与前一个实现只有两个方面不同。首先,类 Capped2 现在还扩展 IterableOps[A, Capped2, Capped2[A]]。其次,覆盖其 iterableFactory 成员以返回 IterableFactory[Capped2]。如前几节所述,IterableOps 特征以通用方式实现了 Iterable 的所有具体方法。例如,take、drop、filter 或 init 等方法的返回类型是传递给类 IterableOps 的第三个类型参数,即在类 Capped2 中,它是 Capped2[A]。类似地,map、flatMap 或 concat 等方法的返回类型由传递给类 IterableOps 的第二个类型参数定义,即在类 Capped2 中,它就是 Capped2 本身。
返回 Capped2[A] 集合的操作在 IterableOps 中通过 fromSpecific 和 newSpecificBuilder 操作实现。父类 immutable.Iterable[A] 实现 fromSpecific 和 newSpecificBuilder,使得它们仅返回 immutable.Iterable[A] 集合,而不是预期的 Capped2[A] 集合。因此,我们覆盖 fromSpecific 和 newSpecificBuilder 操作,使其返回 Capped2[A] 集合。另一个返回类型过于通用的继承操作是 empty。我们覆盖它以返回 Capped2[A] 集合。所有这些覆盖都简单地转发到 iterableFactory 成员引用的集合工厂,其值为 Capped2Factory 类的实例。
Capped2Factory 类提供便捷的工厂方法来构建集合。最终,这些方法委托给 empty 操作,该操作构建一个空的 Capped2 实例,以及 newBuilder,该操作使用 appended 操作来扩展 Capped2 集合。
通过 Capped2 类 的精细实现,转换操作现在按预期工作,并且 Capped2Factory 类从其他集合提供无缝转换
scala> object Capped extends Capped2Factory(capacity = 4)
defined object Capped
scala> Capped(1, 2, 3)
val res0: Capped2[Int] = Capped2(1, 2, 3)
scala> res0.take(2)
val res1: Capped2[Int] = Capped2(1, 2)
scala> res0.filter(x => x % 2 == 1)
val res2: Capped2[Int] = Capped2(1, 3)
scala> res0.map(x => x * x)
val res3: Capped2[Int] = Capped2(1, 4, 9)
scala> List(1, 2, 3, 4, 5).to(Capped)
val res4: Capped2[Int] = Capped2(2, 3, 4, 5)
此实现现在行为正确,但我们仍可以改进一些内容
- 由于我们的集合是严格的,我们可以利用转换操作的严格实现提供的更好性能,
- 由于我们的
fromSpecific、newSpecificBuilder和empty操作仅转发到iterableFactory成员,我们可以使用提供此类实现的IterableFactoryDefaults特征。
Capped 类的最终版本
import scala.collection._
final class Capped[A] private (val capacity: Int, val length: Int, offset: Int, elems: Array[Any])
extends immutable.Iterable[A]
with IterableOps[A, Capped, Capped[A]]
with IterableFactoryDefaults[A, Capped]
with StrictOptimizedIterableOps[A, Capped, Capped[A]] { self =>
def this(capacity: Int) =
this(capacity, length = 0, offset = 0, elems = Array.ofDim(capacity))
def appended[B >: A](elem: B): Capped[B] = {
val newElems = Array.ofDim[Any](capacity)
Array.copy(elems, 0, newElems, 0, capacity)
val (newOffset, newLength) =
if (length == capacity) {
newElems(offset) = elem
((offset + 1) % capacity, length)
} else {
newElems(length) = elem
(offset, length + 1)
}
new Capped[B](capacity, newLength, newOffset, newElems)
}
@`inline` def :+ [B >: A](elem: B): Capped[B] = appended(elem)
def apply(i: Int): A = elems((i + offset) % capacity).asInstanceOf[A]
def iterator: Iterator[A] = view.iterator
override def view: IndexedSeqView[A] = new IndexedSeqView[A] {
def length: Int = self.length
def apply(i: Int): A = self(i)
}
override def knownSize: Int = length
override def className = "Capped"
override val iterableFactory: IterableFactory[Capped] = new CappedFactory(capacity)
}
class CappedFactory(capacity: Int) extends IterableFactory[Capped] {
def from[A](source: IterableOnce[A]): Capped[A] =
source match {
case capped: Capped[A] if capped.capacity == capacity => capped
case _ => (newBuilder[A] ++= source).result()
}
def empty[A]: Capped[A] = new Capped[A](capacity)
def newBuilder[A]: mutable.Builder[A, Capped[A]] =
new mutable.ImmutableBuilder[A, Capped[A]](empty) {
def addOne(elem: A): this.type = { elems = elems :+ elem; this }
}
}
import scala.collection.*
final class Capped[A] private (val capacity: Int, val length: Int, offset: Int, elems: Array[Any])
extends immutable.Iterable[A],
IterableOps[A, Capped, Capped[A]],
IterableFactoryDefaults[A, Capped],
StrictOptimizedIterableOps[A, Capped, Capped[A]]:
self =>
def this(capacity: Int) =
this(capacity, length = 0, offset = 0, elems = Array.ofDim(capacity))
def appended[B >: A](elem: B): Capped[B] =
val newElems = Array.ofDim[Any](capacity)
Array.copy(elems, 0, newElems, 0, capacity)
val (newOffset, newLength) =
if length == capacity then
newElems(offset) = elem
((offset + 1) % capacity, length)
else
newElems(length) = elem
(offset, length + 1)
Capped[B](capacity, newLength, newOffset, newElems)
end appended
inline def :+ [B >: A](elem: B): Capped[B] = appended(elem)
def apply(i: Int): A = elems((i + offset) % capacity).asInstanceOf[A]
def iterator: Iterator[A] = view.iterator
override def view: IndexedSeqView[A] = new IndexedSeqView[A]:
def length: Int = self.length
def apply(i: Int): A = self(i)
override def knownSize: Int = length
override def className = "Capped"
override val iterableFactory: IterableFactory[Capped] = new CappedFactory(capacity)
end Capped
class CappedFactory(capacity: Int) extends IterableFactory[Capped]:
def from[A](source: IterableOnce[A]): Capped[A] =
source match
case capped: Capped[?] if capped.capacity == capacity => capped.asInstanceOf[Capped[A]]
case _ => (newBuilder[A] ++= source).result()
def empty[A]: Capped[A] = Capped[A](capacity)
def newBuilder[A]: mutable.Builder[A, Capped[A]] =
new mutable.ImmutableBuilder[A, Capped[A]](empty):
def addOne(elem: A): this.type = { elems = elems :+ elem; this }
end CappedFactory
就是这样。最终 Capped 类
- 扩展
StrictOptimizedIterableOps特征,该特征覆盖所有转换操作以利用严格构建器, - 扩展
IterableFactoryDefaults特征,该特征覆盖fromSpecific、newSpecificBuilder和empty操作以转发到iterableFactory, - 为性能覆盖一些操作:
view现在使用索引访问,iterator委托给视图。knownSize操作也已覆盖,因为大小始终已知。
其实现需要一点协议。从本质上讲,你必须从 Ops 模板特征继承,而不仅仅是从集合类型继承,覆盖 iterableFactory 成员以返回更具体的工厂,最后实现抽象方法(例如,在本例中为 iterator),如果有的话。
RNA 序列
从第二个示例开始,假设你要为 RNA 链创建新的不可变序列类型。这些是碱基 A(腺嘌呤)、U(尿嘧啶)、G(鸟嘌呤)和 C(胞嘧啶)的序列。碱基的定义如下面 RNA 碱基列表中所示
abstract class Base
case object A extends Base
case object U extends Base
case object G extends Base
case object C extends Base
object Base {
val fromInt: Int => Base = Array(A, U, G, C)
val toInt: Base => Int = Map(A -> 0, U -> 1, G -> 2, C -> 3)
}
每个碱基被定义为从公共抽象类 Base 继承的 case 对象。Base 类有一个伴随对象,该对象定义两个在碱基和整数 0 到 3 之间进行映射的函数。
你可以在上面的示例中看到使用集合来实现这些函数的两种不同方法。toInt 函数实现为从 Base 值到整数的 Map。fromInt 反向函数实现为一个数组。这利用了映射和数组是函数这一事实,因为它们继承自 Function1 特征。
enum Base:
case A, U, G, C
object Base:
val fromInt: Int => Base = values
val toInt: Base => Int = _.ordinal
每个基础都定义为 Base 枚举的一个案例。 Base 有一个伴随对象,该对象定义了两个函数,用于在基础和整数 0 到 3 之间进行映射。
toInt 函数通过委托给 Base 上定义的 ordinal 方法来实现,该方法会自动定义,因为 Base 是一个枚举。每个枚举案例都将有一个唯一的 ordinal 值。反向函数 fromInt 实现为一个数组。这利用了数组是函数这一事实,因为它们继承自 Function1 特征。
下一个任务是为 RNA 链定义一个类。从概念上讲,RNA 链只是一个 Seq[Base]。但是,RNA 链可能会变得很长,因此在紧凑表示上投入一些工作是有意义的。由于只有四个碱基,因此可以用两位来识别一个碱基,因此你可以将十六个碱基作为两位值存储在一个整数中。然后,这个想法是构建 Seq[Base] 的一个专门子类,它使用这种打包表示。
RNA 链类的第一个版本
import collection.mutable
import collection.immutable.{ IndexedSeq, IndexedSeqOps }
final class RNA1 private (
val groups: Array[Int],
val length: Int
) extends IndexedSeq[Base]
with IndexedSeqOps[Base, IndexedSeq, RNA1] {
import RNA1._
def apply(idx: Int): Base = {
if (idx < 0 || length <= idx)
throw new IndexOutOfBoundsException
Base.fromInt(groups(idx / N) >> (idx % N * S) & M)
}
override protected def fromSpecific(coll: IterableOnce[Base]): RNA1 =
fromSeq(coll.iterator.toSeq)
override protected def newSpecificBuilder: mutable.Builder[Base, RNA1] =
iterableFactory.newBuilder[Base].mapResult(fromSeq)
override def empty: RNA1 = fromSeq(Seq.empty)
override def className = "RNA1"
}
object RNA1 {
// Number of bits necessary to represent group
private val S = 2
// Number of groups that fit in an Int
private val N = 32 / S
// Bitmask to isolate a group
private val M = (1 << S) - 1
def fromSeq(buf: collection.Seq[Base]): RNA1 = {
val groups = new Array[Int]((buf.length + N - 1) / N)
for (i <- 0 until buf.length)
groups(i / N) |= Base.toInt(buf(i)) << (i % N * S)
new RNA1(groups, buf.length)
}
def apply(bases: Base*) = fromSeq(bases)
}
import collection.mutable
import collection.immutable.{ IndexedSeq, IndexedSeqOps }
final class RNA1 private
( val groups: Array[Int],
val length: Int
) extends IndexedSeq[Base],
IndexedSeqOps[Base, IndexedSeq, RNA1]:
import RNA1.*
def apply(idx: Int): Base =
if idx < 0 || length <= idx then
throw IndexOutOfBoundsException()
Base.fromInt(groups(idx / N) >> (idx % N * S) & M)
override protected def fromSpecific(coll: IterableOnce[Base]): RNA1 =
fromSeq(coll.iterator.toSeq)
override protected def newSpecificBuilder: mutable.Builder[Base, RNA1] =
iterableFactory.newBuilder[Base].mapResult(fromSeq)
override def empty: RNA1 = fromSeq(Seq.empty)
override def className = "RNA1"
end RNA1
object RNA1:
// Number of bits necessary to represent group
private val S = 2
// Number of groups that fit in an Int
private val N = 32 / S
// Bitmask to isolate a group
private val M = (1 << S) - 1
def fromSeq(buf: collection.Seq[Base]): RNA1 =
val groups = new Array[Int]((buf.length + N - 1) / N)
for i <- 0 until buf.length do
groups(i / N) |= Base.toInt(buf(i)) << (i % N * S)
new RNA1(groups, buf.length)
def apply(bases: Base*) = fromSeq(bases)
end RNA1
上面的 RNA 链类列表展示了该类的第一个版本。类 RNA1 有一个构造函数,它将一个 Int 数组作为其第一个参数。此数组包含打包的 RNA 数据,每个元素中有十六个碱基,最后一个数组元素除外,它可能被部分填充。第二个参数 length 指定数组(和序列)上的碱基总数。类 RNA1 扩展 IndexedSeq[Base] 和 IndexedSeqOps[Base, IndexedSeq, RNA1]。这些特征定义了以下抽象方法
length,通过定义同名参数字段自动实现,apply(索引方法),通过首先从groups数组中提取一个整数,然后使用右移 (>>) 和掩码 (&) 从该整数中提取正确的两位数来实现。私有常量S、N和M来自RNA1伴随对象。S指定每个数据包的大小(即,两个);N指定每个整数的两位数据包的数量;M是一个位掩码,它隔离了一个字中的最低S位。
我们还覆盖了以下由转换操作(如 filter 和 take)使用的成员
fromSpecific,由RNA1伴随对象的fromSeq方法实现,newSpecificBuilder,通过使用默认IndexedSeq构建器并通过mapResult方法将其结果转换为RNA1来实现。
请注意,类 RNA1 的构造函数是 private。这意味着客户端不能通过调用 new 来创建 RNA1 序列,这是有道理的,因为它隐藏了 RNA1 序列在打包数组中的表示形式。如果客户端无法看到 RNA 序列的表示形式,那么就可以在未来任何时候更改这些表示形式,而不会影响客户端代码。换句话说,这种设计实现了 RNA 序列的接口及其实现的良好解耦。但是,如果使用 new 构建 RNA 序列是不可能的,那么一定有其他方法来创建新的 RNA 序列,否则整个类将毫无用处。事实上,有两种创建 RNA 序列的备选方案,都由 RNA1 伴随对象提供。第一种方法是 fromSeq 方法,它将给定的碱基序列(即,Seq[Base] 类型的变量)转换为 RNA1 类的实例。fromSeq 方法通过将参数序列中包含的所有碱基打包到一个数组中,然后使用该数组和原始序列的长度作为参数调用 RNA1 的私有构造函数来实现这一点。这利用了这样一个事实:类的私有构造函数在类的伴随对象中是可见的。
创建 RNA1 值的第二种方法是由 RNA1 对象中的 apply 方法提供的。它接受可变数量的 Base 参数,并简单地将它们作为序列转发给 fromSeq。以下是两种创建方案的实际操作
scala> val xs = List(A, G, U, A)
val xs: List[Base] = List(A, G, U, A)
scala> RNA1.fromSeq(xs)
val res1: RNA1 = RNA1(A, G, U, A)
scala> val rna1 = RNA1(A, U, G, G, C)
val rna1: RNA1 = RNA1(A, U, G, G, C)
还要注意,我们继承自 IndexedSeqOps 特性的类型参数是:Base、IndexedSeq 和 RNA1。第一个代表元素类型,第二个代表转换操作使用的类型构造器,该操作返回具有不同元素类型的集合,第三个代表转换操作使用的类型,该操作返回具有相同元素类型的集合。在我们的示例中,值得注意的是,第二个是 IndexedSeq,而第三个是 RNA1。这意味着诸如 map 或 flatMap 的操作返回 IndexedSeq,而诸如 take 或 filter 的操作返回 RNA1。
以下示例展示了 take 和 filter 的用法
scala> val rna1_2 = rna1.take(3)
val rna1_2: RNA1 = RNA1(A, U, G)
scala> val rna1_3 = rna1.filter(_ != U)
val rna1_3: RNA1 = RNA1(A, G, G, C)
处理 map 及类似方法
但是,返回具有不同元素类型的集合的转换操作始终返回 IndexedSeq。
如何将这些方法调整为 RNA 链?理想的行为是在将碱基映射到碱基或使用 ++ 追加两个 RNA 链时,返回 RNA 链
scala> val rna = RNA(A, U, G, G, C)
val rna: RNA = RNA(A, U, G, G, C)
scala> rna.map { case A => U case b => b }
val res7: RNA = RNA(U, U, G, G, C)
scala> rna ++ rna
val res8: RNA = RNA(A, U, G, G, C, A, U, G, G, C)
另一方面,将碱基映射到 RNA 链上的其他类型无法生成另一个 RNA 链,因为新元素的类型错误。它必须生成序列。同样,将非 Base 类型的元素追加到 RNA 链可以生成常规序列,但无法生成另一个 RNA 链。
scala> rna.map(Base.toInt)
val res2: IndexedSeq[Int] = Vector(0, 1, 2, 2, 3)
scala> rna ++ List("missing", "data")
val res3: IndexedSeq[java.lang.Object] =
Vector(A, U, G, G, C, missing, data)
这是在理想情况下所期望的。但这并不是 RNA1 类 所提供的。实际上,所有示例都将返回 Vector 实例,而不仅仅是后两个。如果使用此类的实例运行以上前三个命令,则会获得
scala> val rna1 = RNA1(A, U, G, G, C)
val rna1: RNA1 = RNA1(A, U, G, G, C)
scala> rna1.map { case A => U case b => b }
val res0: IndexedSeq[Base] = Vector(U, U, G, G, C)
scala> rna1 ++ rna1
val res1: IndexedSeq[Base] = Vector(A, U, G, G, C, A, U, G, G, C)
因此,map 和 ++ 的结果永远不是 RNA 链,即使生成集合的元素类型是 Base。要了解如何做得更好,最好仔细查看 map 方法(或具有类似签名的 ++)的签名。 map 方法最初在 scala.collection.IterableOps 类中定义,其签名如下
def map[B](f: A => B): CC[B]
其中 A 是集合的元素类型,CC 是作为第二个参数传递给 IterableOps 特性的类型构造器。
在我们的 RNA1 实现中,此 CC 类型构造器是 IndexedSeq,这就是我们始终得到 Vector 作为结果的原因。
RNA 链类的第二个版本
import scala.collection.{ View, mutable }
import scala.collection.immutable.{ IndexedSeq, IndexedSeqOps }
final class RNA2 private (val groups: Array[Int], val length: Int)
extends IndexedSeq[Base] with IndexedSeqOps[Base, IndexedSeq, RNA2] {
import RNA2._
def apply(idx: Int): Base = // as before
override protected def fromSpecific(coll: IterableOnce[Base]): RNA2 = // as before
override protected def newSpecificBuilder: mutable.Builder[Base, RNA2] = // as before
override def empty: RNA2 = // as before
override def className = "RNA2"
// Overloading of `appended`, `prepended`, `appendedAll`,
// `prependedAll`, `map`, `flatMap` and `concat` to return an `RNA2`
// when possible
def concat(suffix: IterableOnce[Base]): RNA2 =
fromSpecific(iterator ++ suffix.iterator)
// symbolic alias for `concat`
@inline final def ++ (suffix: IterableOnce[Base]): RNA2 = concat(suffix)
def appended(base: Base): RNA2 =
fromSpecific(new View.Appended(this, base))
def appendedAll(suffix: IterableOnce[Base]): RNA2 =
concat(suffix)
def prepended(base: Base): RNA2 =
fromSpecific(new View.Prepended(base, this))
def prependedAll(prefix: IterableOnce[Base]): RNA2 =
fromSpecific(prefix.iterator ++ iterator)
def map(f: Base => Base): RNA2 =
fromSpecific(new View.Map(this, f))
def flatMap(f: Base => IterableOnce[Base]): RNA2 =
fromSpecific(new View.FlatMap(this, f))
}
import scala.collection.{ View, mutable }
import scala.collection.immutable.{ IndexedSeq, IndexedSeqOps }
final class RNA2 private (val groups: Array[Int], val length: Int)
extends IndexedSeq[Base], IndexedSeqOps[Base, IndexedSeq, RNA2]:
import RNA2.*
def apply(idx: Int): Base = // as before
override protected def fromSpecific(coll: IterableOnce[Base]): RNA2 = // as before
override protected def newSpecificBuilder: mutable.Builder[Base, RNA2] = // as before
override def empty: RNA2 = // as before
override def className = "RNA2"
// Overloading of `appended`, `prepended`, `appendedAll`,
// `prependedAll`, `map`, `flatMap` and `concat` to return an `RNA2`
// when possible
def concat(suffix: IterableOnce[Base]): RNA2 =
fromSpecific(iterator ++ suffix.iterator)
// symbolic alias for `concat`
inline final def ++ (suffix: IterableOnce[Base]): RNA2 = concat(suffix)
def appended(base: Base): RNA2 =
fromSpecific(View.Appended(this, base))
def appendedAll(suffix: IterableOnce[Base]): RNA2 =
concat(suffix)
def prepended(base: Base): RNA2 =
fromSpecific(View.Prepended(base, this))
def prependedAll(prefix: IterableOnce[Base]): RNA2 =
fromSpecific(prefix.iterator ++ iterator)
def map(f: Base => Base): RNA2 =
fromSpecific(View.Map(this, f))
def flatMap(f: Base => IterableOnce[Base]): RNA2 =
fromSpecific(View.FlatMap(this, f))
end RNA2
为了解决此缺陷,您需要重载返回 IndexedSeq[B] 的方法,用于 B 已知为 Base 的情况,以返回 RNA2。
与 类 RNA1 相比,我们为方法 concat、appended、appendedAll、prepended、prependedAll、map 和 flatMap 添加了重载。
此实现现在行为正确,但我们仍然可以改进一些内容。由于我们的集合是严格的,我们可以在转换操作中利用严格构建器提供的更好的性能。此外,如果我们尝试将 Iterable[Base] 转换为 RNA2,它将失败
scala> val bases: Iterable[Base] = List(A, U, C, C)
val bases: Iterable[Base] = List(A, U, C, C)
scala> bases.to(RNA2)
^
error: type mismatch;
found : RNA2.type
required: scala.collection.Factory[Base,?]
scala> val bases: Iterable[Base] = List(A, U, C, C)
val bases: Iterable[Base] = List(A, U, C, C)
scala> bases.to(RNA2)
-- [E007] Type Mismatch Error: -------------------------------------------------
1 |bases.to(RNA2)
| ^^^^
| Found: RNA2.type
| Required: scala.collection.Factory[Base, Any]
|
| longer explanation available when compiling with `-explain`
RNA 链类的最终版本
import scala.collection.{ AbstractIterator, SpecificIterableFactory, StrictOptimizedSeqOps, View, mutable }
import scala.collection.immutable.{ IndexedSeq, IndexedSeqOps }
final class RNA private (
val groups: Array[Int],
val length: Int
) extends IndexedSeq[Base]
with IndexedSeqOps[Base, IndexedSeq, RNA]
with StrictOptimizedSeqOps[Base, IndexedSeq, RNA] { rna =>
import RNA._
// Mandatory implementation of `apply` in `IndexedSeqOps`
def apply(idx: Int): Base = {
if (idx < 0 || length <= idx)
throw new IndexOutOfBoundsException
Base.fromInt(groups(idx / N) >> (idx % N * S) & M)
}
// Mandatory overrides of `fromSpecific`, `newSpecificBuilder`,
// and `empty`, from `IterableOps`
override protected def fromSpecific(coll: IterableOnce[Base]): RNA =
RNA.fromSpecific(coll)
override protected def newSpecificBuilder: mutable.Builder[Base, RNA] =
RNA.newBuilder
override def empty: RNA = RNA.empty
// Overloading of `appended`, `prepended`, `appendedAll`, `prependedAll`,
// `map`, `flatMap` and `concat` to return an `RNA` when possible
def concat(suffix: IterableOnce[Base]): RNA =
strictOptimizedConcat(suffix, newSpecificBuilder)
@inline final def ++ (suffix: IterableOnce[Base]): RNA = concat(suffix)
def appended(base: Base): RNA =
(newSpecificBuilder ++= this += base).result()
def appendedAll(suffix: Iterable[Base]): RNA =
strictOptimizedConcat(suffix, newSpecificBuilder)
def prepended(base: Base): RNA =
(newSpecificBuilder += base ++= this).result()
def prependedAll(prefix: Iterable[Base]): RNA =
(newSpecificBuilder ++= prefix ++= this).result()
def map(f: Base => Base): RNA =
strictOptimizedMap(newSpecificBuilder, f)
def flatMap(f: Base => IterableOnce[Base]): RNA =
strictOptimizedFlatMap(newSpecificBuilder, f)
// Optional re-implementation of iterator,
// to make it more efficient.
override def iterator: Iterator[Base] = new AbstractIterator[Base] {
private var i = 0
private var b = 0
def hasNext: Boolean = i < rna.length
def next(): Base = {
b = if (i % N == 0) groups(i / N) else b >>> S
i += 1
Base.fromInt(b & M)
}
}
override def className = "RNA"
}
object RNA extends SpecificIterableFactory[Base, RNA] {
private val S = 2 // number of bits in group
private val M = (1 << S) - 1 // bitmask to isolate a group
private val N = 32 / S // number of groups in an Int
def fromSeq(buf: collection.Seq[Base]): RNA = {
val groups = new Array[Int]((buf.length + N - 1) / N)
for (i <- 0 until buf.length)
groups(i / N) |= Base.toInt(buf(i)) << (i % N * S)
new RNA(groups, buf.length)
}
// Mandatory factory methods: `empty`, `newBuilder`
// and `fromSpecific`
def empty: RNA = fromSeq(Seq.empty)
def newBuilder: mutable.Builder[Base, RNA] =
mutable.ArrayBuffer.newBuilder[Base].mapResult(fromSeq)
def fromSpecific(it: IterableOnce[Base]): RNA = it match {
case seq: collection.Seq[Base] => fromSeq(seq)
case _ => fromSeq(mutable.ArrayBuffer.from(it))
}
}
import scala.collection.{ AbstractIterator, SpecificIterableFactory, StrictOptimizedSeqOps, View, mutable }
import scala.collection.immutable.{ IndexedSeq, IndexedSeqOps }
final class RNA private
( val groups: Array[Int],
val length: Int
) extends IndexedSeq[Base],
IndexedSeqOps[Base, IndexedSeq, RNA],
StrictOptimizedSeqOps[Base, IndexedSeq, RNA]:
rna =>
import RNA.*
// Mandatory implementation of `apply` in `IndexedSeqOps`
def apply(idx: Int): Base =
if idx < 0 || length <= idx then
throw new IndexOutOfBoundsException
Base.fromInt(groups(idx / N) >> (idx % N * S) & M)
// Mandatory overrides of `fromSpecific`, `newSpecificBuilder`,
// and `empty`, from `IterableOps`
override protected def fromSpecific(coll: IterableOnce[Base]): RNA =
RNA.fromSpecific(coll)
override protected def newSpecificBuilder: mutable.Builder[Base, RNA] =
RNA.newBuilder
override def empty: RNA = RNA.empty
// Overloading of `appended`, `prepended`, `appendedAll`, `prependedAll`,
// `map`, `flatMap` and `concat` to return an `RNA` when possible
def concat(suffix: IterableOnce[Base]): RNA =
strictOptimizedConcat(suffix, newSpecificBuilder)
inline final def ++ (suffix: IterableOnce[Base]): RNA = concat(suffix)
def appended(base: Base): RNA =
(newSpecificBuilder ++= this += base).result()
def appendedAll(suffix: Iterable[Base]): RNA =
strictOptimizedConcat(suffix, newSpecificBuilder)
def prepended(base: Base): RNA =
(newSpecificBuilder += base ++= this).result()
def prependedAll(prefix: Iterable[Base]): RNA =
(newSpecificBuilder ++= prefix ++= this).result()
def map(f: Base => Base): RNA =
strictOptimizedMap(newSpecificBuilder, f)
def flatMap(f: Base => IterableOnce[Base]): RNA =
strictOptimizedFlatMap(newSpecificBuilder, f)
// Optional re-implementation of iterator,
// to make it more efficient.
override def iterator: Iterator[Base] = new AbstractIterator[Base]:
private var i = 0
private var b = 0
def hasNext: Boolean = i < rna.length
def next(): Base =
b = if i % N == 0 then groups(i / N) else b >>> S
i += 1
Base.fromInt(b & M)
override def className = "RNA"
end RNA
object RNA extends SpecificIterableFactory[Base, RNA]:
private val S = 2 // number of bits in group
private val M = (1 << S) - 1 // bitmask to isolate a group
private val N = 32 / S // number of groups in an Int
def fromSeq(buf: collection.Seq[Base]): RNA =
val groups = new Array[Int]((buf.length + N - 1) / N)
for i <- 0 until buf.length do
groups(i / N) |= Base.toInt(buf(i)) << (i % N * S)
new RNA(groups, buf.length)
// Mandatory factory methods: `empty`, `newBuilder`
// and `fromSpecific`
def empty: RNA = fromSeq(Seq.empty)
def newBuilder: mutable.Builder[Base, RNA] =
mutable.ArrayBuffer.newBuilder[Base].mapResult(fromSeq)
def fromSpecific(it: IterableOnce[Base]): RNA = it match
case seq: collection.Seq[Base] => fromSeq(seq)
case _ => fromSeq(mutable.ArrayBuffer.from(it))
end RNA
最终 RNA 类
- 扩展了
StrictOptimizedSeqOps特性,该特性覆盖所有转换操作以利用严格构建器, - 使用
StrictOptimizedSeqOps特性提供的实用程序操作,例如strictOptimizedConcat,以实现返回RNA集合的转换操作的重载, - 有一个伴随对象,它扩展了
SpecificIterableFactory[Base, RNA],这使得可以将其用作to调用的参数(将任何碱基集合转换为RNA,例如List(U, A, G, C).to(RNA)), - 将
newSpecificBuilder和fromSpecific实现移至伴随对象。
到目前为止的讨论都集中在定义新序列所需的最小定义量上,这些定义量使用遵守特定类型的方法。但在实践中,你可能还想为你的序列添加新功能或覆盖现有方法以提高效率。一个例子是类 RNA 中被覆盖的 iterator 方法。 iterator 本身是一个重要的方法,因为它实现了对集合的循环。此外,许多其他集合方法都是根据 iterator 实现的。因此,优化方法的实现是值得的。 IndexedSeq 中 iterator 的标准实现将简单地使用 apply 选择集合的每个第 i 个元素,其中 i 的范围是从 0 到集合长度减一。因此,此标准实现会选择一个数组元素,并为 RNA 链中的每个元素解包一次碱基。类 RNA 中覆盖的 iterator 比这更智能。对于每个选定的数组元素,它会立即将给定的函数应用于其中包含的所有碱基。因此,数组选择和位解包的工作量大大减少。
前缀映射
作为第三个示例,你将了解如何将一种新的可变映射集成到集合框架中。这个想法是通过“Patricia 树”实现一个以 String 作为键类型的可变映射。术语 Patricia 实际上是“Practical Algorithm to Retrieve Information Coded in Alphanumeric”(检索以字母数字编码的信息的实用算法)的缩写,而 trie 来自 retrieval(trie 也称为基数树或前缀树)。这个想法是将集合或映射存储为一棵树,其中搜索键中的后续字符唯一地确定了通过树的路径。例如,存储字符串“abc”、“abd”、“al”、“all”和“xy”的 Patricia 树如下所示
一个示例 Patricia 树: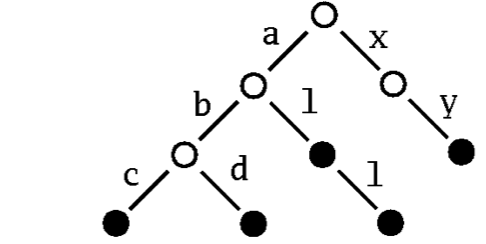
要在此 Trie 中找到对应于字符串“abc”的节点,只需按照标记为“a”的子树,从那里继续到标记为“b”的子树,最终到达标记为“c”的子树即可。如果 Patricia Trie 用作映射,则与键关联的值存储在可以通过该键到达的节点中。如果它是一个集合,则只需存储一个标记,表示该节点存在于该集合中。
Patricia Trie 支持非常高效的查找和更新。另一个不错的功能是它们支持通过给定前缀来选择子集合。例如,在上面的 Patricia 树中,你可以通过从树的根节点沿着“a”链接,轻松获得所有以“a”开头的键的子集合。
基于这些想法,我们现在将引导你完成实现一个作为 Patricia Trie 实现的映射。我们称该映射为 PrefixMap,这意味着它提供了一个方法 withPrefix,该方法选择所有以给定前缀开头的键的子映射。我们首先使用运行示例中显示的键定义一个前缀映射
scala> val m = PrefixMap("abc" -> 0, "abd" -> 1, "al" -> 2,
"all" -> 3, "xy" -> 4)
val m: PrefixMap[Int] = PrefixMap((abc,0), (abd,1), (al,2), (all,3), (xy,4))
然后在 m 上调用 withPrefix 将产生另一个前缀映射
scala> m.withPrefix("a")
val res14: PrefixMap[Int] = PrefixMap((bc,0), (bd,1), (l,2), (ll,3))
Patricia Trie 实现
import scala.collection._
import scala.collection.mutable.{ GrowableBuilder, Builder }
class PrefixMap[A]
extends mutable.Map[String, A]
with mutable.MapOps[String, A, mutable.Map, PrefixMap[A]]
with StrictOptimizedIterableOps[(String, A), mutable.Iterable, PrefixMap[A]] {
private var suffixes: immutable.Map[Char, PrefixMap[A]] = immutable.Map.empty
private var value: Option[A] = None
def get(s: String): Option[A] =
if (s.isEmpty) value
else suffixes.get(s(0)).flatMap(_.get(s.substring(1)))
def withPrefix(s: String): PrefixMap[A] =
if (s.isEmpty) this
else {
val leading = s(0)
suffixes.get(leading) match {
case None =>
suffixes = suffixes + (leading -> empty)
case _ =>
}
suffixes(leading).withPrefix(s.substring(1))
}
def iterator: Iterator[(String, A)] =
(for (v <- value.iterator) yield ("", v)) ++
(for ((chr, m) <- suffixes.iterator;
(s, v) <- m.iterator) yield (chr +: s, v))
def addOne(kv: (String, A)): this.type = {
withPrefix(kv._1).value = Some(kv._2)
this
}
def subtractOne(s: String): this.type = {
if (s.isEmpty) { val prev = value; value = None; prev }
else suffixes.get(s(0)).flatMap(_.remove(s.substring(1)))
this
}
// Overloading of transformation methods that should return a PrefixMap
def map[B](f: ((String, A)) => (String, B)): PrefixMap[B] =
strictOptimizedMap(PrefixMap.newBuilder, f)
def flatMap[B](f: ((String, A)) => IterableOnce[(String, B)]): PrefixMap[B] =
strictOptimizedFlatMap(PrefixMap.newBuilder, f)
// Override `concat` and `empty` methods to refine their return type
override def concat[B >: A](suffix: IterableOnce[(String, B)]): PrefixMap[B] =
strictOptimizedConcat(suffix, PrefixMap.newBuilder)
override def empty: PrefixMap[A] = new PrefixMap
// Members declared in scala.collection.mutable.Clearable
override def clear(): Unit = suffixes = immutable.Map.empty
// Members declared in scala.collection.IterableOps
override protected def fromSpecific(coll: IterableOnce[(String, A)]): PrefixMap[A] = PrefixMap.from(coll)
override protected def newSpecificBuilder: mutable.Builder[(String, A), PrefixMap[A]] = PrefixMap.newBuilder
override def className = "PrefixMap"
}
object PrefixMap {
def empty[A] = new PrefixMap[A]
def from[A](source: IterableOnce[(String, A)]): PrefixMap[A] =
source match {
case pm: PrefixMap[A] => pm
case _ => (newBuilder ++= source).result()
}
def apply[A](kvs: (String, A)*): PrefixMap[A] = from(kvs)
def newBuilder[A]: mutable.Builder[(String, A), PrefixMap[A]] =
new mutable.GrowableBuilder[(String, A), PrefixMap[A]](empty)
import scala.language.implicitConversions
implicit def toFactory[A](self: this.type): Factory[(String, A), PrefixMap[A]] =
new Factory[(String, A), PrefixMap[A]] {
def fromSpecific(it: IterableOnce[(String, A)]): PrefixMap[A] = self.from(it)
def newBuilder: mutable.Builder[(String, A), PrefixMap[A]] = self.newBuilder
}
}
import scala.collection.*
import scala.collection.mutable.{ GrowableBuilder, Builder }
class PrefixMap[A]
extends mutable.Map[String, A],
mutable.MapOps[String, A, mutable.Map, PrefixMap[A]],
StrictOptimizedIterableOps[(String, A), mutable.Iterable, PrefixMap[A]]:
private var suffixes: immutable.Map[Char, PrefixMap[A]] = immutable.Map.empty
private var value: Option[A] = None
def get(s: String): Option[A] =
if s.isEmpty then value
else suffixes.get(s(0)).flatMap(_.get(s.substring(1)))
def withPrefix(s: String): PrefixMap[A] =
if s.isEmpty then this
else
val leading = s(0)
suffixes.get(leading) match
case None =>
suffixes = suffixes + (leading -> empty)
case _ =>
suffixes(leading).withPrefix(s.substring(1))
def iterator: Iterator[(String, A)] =
(for v <- value.iterator yield ("", v)) ++
(for (chr, m) <- suffixes.iterator
(s, v) <- m.iterator yield (chr +: s, v))
def addOne(kv: (String, A)): this.type =
withPrefix(kv._1).value = Some(kv._2)
this
def subtractOne(s: String): this.type =
if s.isEmpty then { val prev = value; value = None; prev }
else suffixes.get(s(0)).flatMap(_.remove(s.substring(1)))
this
// Overloading of transformation methods that should return a PrefixMap
def map[B](f: ((String, A)) => (String, B)): PrefixMap[B] =
strictOptimizedMap(PrefixMap.newBuilder, f)
def flatMap[B](f: ((String, A)) => IterableOnce[(String, B)]): PrefixMap[B] =
strictOptimizedFlatMap(PrefixMap.newBuilder, f)
// Override `concat` and `empty` methods to refine their return type
override def concat[B >: A](suffix: IterableOnce[(String, B)]): PrefixMap[B] =
strictOptimizedConcat(suffix, PrefixMap.newBuilder)
override def empty: PrefixMap[A] = PrefixMap()
// Members declared in scala.collection.mutable.Clearable
override def clear(): Unit = suffixes = immutable.Map.empty
// Members declared in scala.collection.IterableOps
override protected def fromSpecific(coll: IterableOnce[(String, A)]): PrefixMap[A] = PrefixMap.from(coll)
override protected def newSpecificBuilder: mutable.Builder[(String, A), PrefixMap[A]] = PrefixMap.newBuilder
override def className = "PrefixMap"
end PrefixMap
object PrefixMap:
def empty[A] = new PrefixMap[A]
def from[A](source: IterableOnce[(String, A)]): PrefixMap[A] =
source match
case pm: PrefixMap[A @unchecked] => pm
case _ => (newBuilder ++= source).result()
def apply[A](kvs: (String, A)*): PrefixMap[A] = from(kvs)
def newBuilder[A]: mutable.Builder[(String, A), PrefixMap[A]] =
mutable.GrowableBuilder[(String, A), PrefixMap[A]](empty)
import scala.language.implicitConversions
implicit def toFactory[A](self: this.type): Factory[(String, A), PrefixMap[A]] =
new Factory[(String, A), PrefixMap[A]]:
def fromSpecific(it: IterableOnce[(String, A)]): PrefixMap[A] = self.from(it)
def newBuilder: mutable.Builder[(String, A), PrefixMap[A]] = self.newBuilder
end PrefixMap
前面的清单显示了 PrefixMap 的定义。该映射的键类型为 String,而值是参数类型 A。它扩展了 mutable.Map[String, A] 和 mutable.MapOps[String, A, mutable.Map, PrefixMap[A]]。你已经在 RNA 链示例中为序列看到了此模式;然后,现在继承一个实现类(如 MapOps)用于获取诸如 filter 之类的转换的正确结果类型。
前缀映射节点有两个可变字段:suffixes 和 value。value 字段包含与该节点关联的可选值。它被初始化为 None。suffixes 字段包含从字符到 PrefixMap 值的映射。它被初始化为空映射。
你可能会问,为什么我们选择一个不可变映射作为 suffixes 的实现类型?由于 PrefixMap 作为一个整体也是可变的,因此可变映射不是更标准吗?答案是,仅包含几个元素的不可变映射在空间和执行时间上都非常高效。例如,包含少于 5 个元素的映射表示为单个对象。相比之下,标准的可变映射是 HashMap,即使它为空,它通常也会占用大约 80 个字节。因此,如果小集合很常见,则最好选择不可变而不是可变。在 Patricia Trie 的情况下,我们期望除了树最顶部的节点之外,大多数节点只包含几个后继。因此,将这些后继存储在不可变映射中可能会更有效率。
现在来看看一个映射需要实现的第一个方法:get。算法如下:要获取前缀映射中与空字符串关联的值,只需选择存储在树根(当前映射)中的可选value。否则,如果键字符串不为空,请尝试选择对应于字符串第一个字符的子映射。如果得到一个映射,请继续查找该映射中第一个字符之后的键字符串的其余部分。如果选择失败,则该键未存储在映射中,因此返回None。使用opt.flatMap(x => f(x))可以优雅地表示对选项值opt的组合选择。当应用于None的可选值时,它将返回None。否则opt为Some(x),并且函数f应用于封装的值x,生成一个新选项,该选项由 flatmap 返回。
可变映射要实现的下一个两个方法是addOne和subtractOne。
subtractOne方法与get非常相似,只是在返回任何关联值之前,将包含该值的字段设置为None。addOne方法首先调用withPrefix导航到需要更新的树节点,然后将该节点的value字段设置为给定值。withPrefix方法遍历树,并在必要时创建子映射,如果某个字符前缀尚未包含在树中作为路径。
可变映射中要实现的最后一个抽象方法是 iterator。此方法需要生成一个迭代器,该迭代器产生存储在映射中的所有键/值对。对于任何给定的前缀映射,此迭代器由以下部分组成:首先,如果映射在其根处的 value 字段中包含一个已定义的值 Some(x),则 ("", x) 是从迭代器返回的第一个元素。此外,迭代器需要遍历存储在 suffixes 字段中的所有子映射的迭代器,但它需要在这些迭代器返回的每个键字符串前添加一个字符。更准确地说,如果 m 是通过字符 chr 从根到达的子映射,并且 (s, v) 是从 m.iterator 返回的一个元素,则根的迭代器将返回 (chr +: s, v)。此逻辑在 PrefixMap 中 iterator 方法的实现中,以两个 for 表达式的连接形式简洁地实现。第一个 for 表达式遍历 value.iterator。这利用了 Option 值定义了一个迭代器方法,如果选项值为 None,则该方法不返回任何元素,如果选项值为 Some(x),则该方法返回一个元素 x。
但是,在所有这些情况下,要构建正确类型的集合,您需要从该类型的空集合开始。这是由 empty 方法提供的,该方法简单地返回一个新的 PrefixMap。
现在,我们将转向伴生对象 PrefixMap。实际上,严格来说,没有必要定义此伴生对象,因为类 PrefixMap 可以独立存在。对象 PrefixMap 的主要目的是定义一些方便的工厂方法。它还定义了一个隐式转换为 Factory,以便与其他集合更好地互操作。当您编写以下内容时,会触发此转换,例如 List("foo" -> 3).to(PrefixMap)。 to 操作将 Factory 作为参数,但 PrefixMap 伴生对象不扩展 Factory(并且它不能扩展,因为 Factory 修复了集合元素的类型,而 PrefixMap 具有多态值类型)。
两个便捷方法是 empty 和 apply。Scala 集合框架中的所有其他集合都存在相同的方法,因此在此处定义它们也有意义。使用这两个方法,您可以像处理任何其他集合一样编写 PrefixMap 字面量
scala> PrefixMap("hello" -> 5, "hi" -> 2)
val res0: PrefixMap[Int] = PrefixMap(hello -> 5, hi -> 2)
scala> res0 += "foo" -> 3
val res1: res0.type = PrefixMap(hello -> 5, hi -> 2, foo -> 3)
摘要
总结一下,如果您想将新的集合类完全集成到框架中,则需要关注以下几点
- 确定集合应该是可变的还是不可变的。
- 为集合选择正确的基本特征。
- 从正确的实现特征继承以实现大多数集合操作。
- 重载默认情况下不返回集合的操作,使其尽可能具体。附录中给出了此类操作的完整列表。
您现在已经了解了 Scala 集合的构建方式以及如何添加新的集合类型。由于 Scala 对抽象的丰富支持,每个新的集合类型都有大量的方法,而无需全部重新实现。
致谢
此页面包含改编自 Odersky、Spoon 和 Venners 撰写的书籍 Programming in Scala 中的材料。我们感谢 Artima 同意将其出版。
附录:支持“相同结果类型”原则的重载方法
您希望添加重载以专门化转换操作,以便它们返回更具体的结果类型。示例是
- 当映射函数返回
Char时,StringOps上的map应返回String(而不是IndexedSeq), - 当映射函数返回对时,
Map上的map应返回Map(而不是Iterable), - 当为结果元素类型提供隐式
Ordering时,SortedSet上的map应返回SortedSet(而不是Set)。
通常,当集合修复其模板特征的某个类型参数时,就会发生这种情况。例如,对于 RNA 集合类型,我们将元素类型固定为 Base,对于 PrefixMap[A] 集合类型,我们将键的类型固定为 String。
下表列出了可能返回不可取的宽类型的转换操作。您可能希望重载这些操作以返回更具体类型。
| 集合 | 操作 |
|---|---|
可迭代对象 |
map、flatMap、collect、scanLeft、scanRight、groupMap、concat、zip、zipAll、unzip |
序列 |
prepended、appended、prependedAll、appendedAll、padTo、patch |
不可变序列 |
updated |
有序集合 |
map、flatMap、collect、zip |
映射 |
map、flatMap、collect、concat |
不可变映射 |
updated、transform |
有序映射 |
map、flatMap、collect、concat |
不可变有序映射 |
updated |
附录:交叉构建自定义集合
由于 Scala 2.13 集合的新内部 API 与之前的集合 API 非常不同,自定义集合类型的作者应使用单独的源目录(按 Scala 版本)来定义它们。
使用 sbt,可以通过向项目添加以下设置来实现此目的
// Adds a `src/main/scala-2.13+` source directory for Scala 2.13 and newer
// and a `src/main/scala-2.13-` source directory for Scala version older than 2.13
unmanagedSourceDirectories in Compile += {
val sourceDir = (sourceDirectory in Compile).value
CrossVersion.partialVersion(scalaVersion.value) match {
case Some((2, n)) if n >= 13 => sourceDir / "scala-2.13+"
case _ => sourceDir / "scala-2.13-"
}
}
然后,可以在 src/main/scala-2.13+ 源目录中定义集合的与 Scala 2.13 兼容的实现,并在 src/main/scala-2.13- 源目录中定义针对之前 Scala 版本的实现。
您可以在 scalacheck 和 scalaz 中看到此方法的实际应用。