作者:Jacob Wang
简介
对于任何高效的软件生态系统而言,一套多样化且全面的库都非常重要。虽然开发和分发 Scala 库很容易,但优秀的库创作不仅仅是编写代码并发布它。
在本指南中,我们将介绍二进制兼容性这个重要主题
- 二进制不兼容性如何导致应用程序中的生产故障
- 如何避免破坏二进制兼容性
- 如何推理和传达其代码更改的影响
在开始之前,让我们了解如何在 Java 虚拟机 (JVM) 上编译和执行代码。
JVM 执行模型
Scala 被编译为称为JVM 字节码的平台无关格式,并存储在 .class 文件中。这些类文件在 JAR 文件中整理以供分发。
当某些代码依赖于库时,其编译的字节码会引用库的字节码。库的字节码由其类/方法签名引用,并在运行时由 JVM 类加载器延迟加载。如果找不到与签名匹配的类或方法,则会抛出异常。
由于此执行模型
- 由于库的字节码仅被引用,未合并到其用户的字节码中,因此在启动应用程序时,我们需要提供依赖树中使用的每个库的 JAR
- 由于延迟加载,缺少类/方法的问题可能仅在应用程序运行一段时间后才会出现。
类加载失败的常见异常包括 InvocationTargetException、ClassNotFoundException、MethodNotFoundException 和 AbstractMethodError。
我们通过一个示例来说明这一点
考虑一个应用程序 App,它依赖于 A,而 A 本身依赖于库 C。在启动应用程序时,我们需要提供所有 App、A 和 C 的类文件(类似于 java -cp App.jar:A.jar:C.jar:. MainClass)。如果我们未提供 C.jar,或者我们提供的 C.jar 不包含 A 调用的某些类/方法,那么当我们的代码尝试调用缺少的类/方法时,我们将获得类加载异常。
这些就是我们所说的链接错误——在运行时无法解析编译的字节码引用的名称时发生的错误。
Scala.js 和 Scala Native 呢?
与 JVM 类似,Scala.js 和 Scala Native 具有各自的 .class 文件等效项,即 .sjsir 文件和 .nir 文件。与 .class 文件类似,它们分布在 .jar 中并在最后链接在一起。
但是,与 JVM 相反,Scala.js 和 Scala Native 在链接时链接各自的 IR 文件,因此是急切的,而不是在运行时延迟的。未能正确链接整个程序会导致在尝试调用 fastOptJS/fullOptJS 或 nativeLink 时报告链接错误。
此外,在链接错误的时间方面存在差异,这些模型极其相似。除非另有说明,本指南的内容同样适用于 JVM、Scala.js 和 Scala Native。
在我们探讨如何避免二进制不兼容错误之前,让我们先确定本指南的其余部分将使用的某些关键术语。
什么是驱逐、源兼容性和二进制兼容性?
驱逐
在执行期间需要某个类时,JVM 类加载器会从类路径中加载第一个匹配的类文件(将忽略任何其他匹配的类文件)。因此,在类路径中拥有同一库的多个版本通常是不希望的
- 需要获取并捆绑多个库版本,而实际只使用一个
- 如果类文件的顺序发生更改,则会出现意外的运行时行为
因此,诸如 sbt 和 Gradle 之类的构建工具将在解析用于编译和打包的 JAR 时选择一个版本,并驱逐其余版本。默认情况下,它们会选择每个库的最新版本,但如果需要,也可以指定其他版本。
源兼容性
如果将一个库版本替换为另一个库版本不会产生任何编译错误或意外的行为更改(语义错误),则这两个库版本是源兼容的。
例如,如果我们可以将某个依赖项的 v1.0.0 升级到 v1.1.0,并且在没有任何编译错误或语义错误的情况下重新编译我们的代码,则 v1.1.0 与 v1.0.0 源兼容。
二进制兼容性
如果这些版本的已编译字节码可以在不导致链接错误的情况下进行互换,则这两个库版本是二进制兼容的。
源兼容性和二进制兼容性之间的关系
虽然破坏源兼容性通常也会导致二进制不兼容性,但它们实际上是正交的——破坏一个并不意味着破坏另一个。
向前兼容性和向后兼容性
在我们描述库版本的兼容性时,有两个“方向”
向后兼容意味着可以在预期旧版本的环境中使用较新的库版本。在讨论二进制和源兼容性时,这是常见且隐含的方向。
向前兼容意味着可以在预期较新版本的环境中使用较旧的库。通常不会为库维护向前兼容性。
让我们看一个示例,其中库 A v1.0.0 与库 C v1.1.0 一起编译。
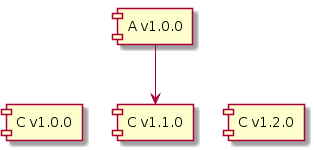
如果我们可以在运行时使用 v1.0.0 的 JAR 而不用 v1.1.0 的 JAR,且没有任何链接错误,则 C v1.1.0 是与 v1.0.0 向前二进制兼容的。
如果我们可以在运行时使用 v1.2.0 的 JAR 而不用 v1.1.0 的 JAR,且没有任何链接错误,则 C v1.2.0 是与 v1.1.0 向后二进制兼容的。
二进制兼容性为何重要
二进制兼容性很重要,因为破坏二进制兼容性会对软件周围的生态系统产生不良后果。
- 最终用户必须在所有依赖项树中以传递方式更新版本,以便它们二进制兼容。此过程既费时又容易出错,并且可能更改最终程序的语义。
- 库作者需要更新其库依赖项,以避免“落后”并为其用户造成依赖关系混乱。频繁的二进制中断会增加维护库所需的工作量。
库中持续的二进制兼容性中断,尤其是其他库使用的库,对我们的生态系统有害,因为它们需要最终用户和依赖库的维护人员花费时间和精力来解决。
让我们看一个二进制不兼容可能导致悲伤和沮丧的示例
“依赖关系混乱”示例
我们的应用程序 App 依赖于库 A 和 B。 A 和 B 都依赖于库 C。最初, A 和 B 都依赖于 C v1.0.0。
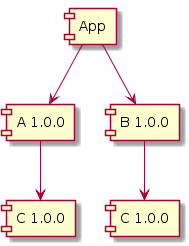
一段时间后,我们看到 B v1.1.0 可用,并在我们的构建中升级了其版本。我们的代码编译并似乎可以工作,所以我们将其推送到生产环境并回家吃饭。
不幸的是,凌晨 2 点,我们接到客户的疯狂电话,说我们的应用程序崩溃了!查看日志,您发现 A 中的某些代码抛出了大量 NoSuchMethodError!
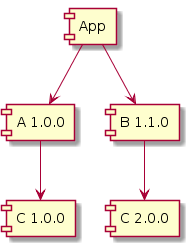
我们为什么收到 NoSuchMethodError?请记住, A v1.0.0 是使用 C v1.0.0 编译的,因此调用 C v1.0.0 中可用的方法。
虽然 B v1.1.0 和 App 已使用 C v2.0.0 重新编译,但 A v1.0.0 的字节码未更改 - 它仍然调用 C v2.0.0 中现已缺少的方法!
此情况只能通过确保所选版本的 C 与依赖项树中 C 的所有其他已驱逐版本二进制兼容来解决。在这种情况下,我们需要一个新版本的 A,它依赖于 C v2.0.0(或任何其他与 C v2.0.0 二进制兼容的未来 C 版本)。
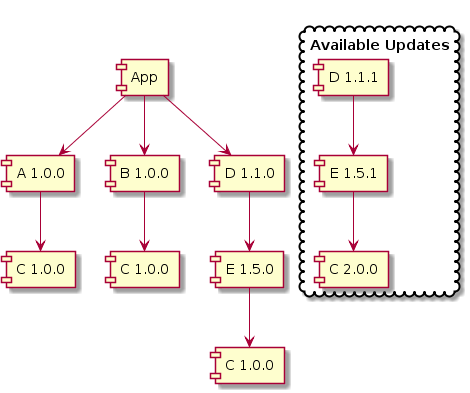
现在想象一下,如果 App 更复杂,有很多依赖项本身依赖于 C(直接或间接) - 升级任何依赖项变得极其困难,因为它现在引入了一个与依赖项树中 C 的其他版本不兼容的 C 版本!
在下面的示例中,我们无法升级到 D v1.1.1,因为它将间接引入 C v2.0.0,从而由于二进制不兼容而导致中断。这种无法在不破坏任何内容的情况下升级任何软件包的情况通常称为依赖项地狱。
作为库作者,我们如何才能让我们的用户免受运行时错误和依赖项地狱的困扰?
- 在发布新库版本之前,使用迁移管理器 (MiMa) 来捕获意外的二进制兼容性中断
- 通过仔细设计和演化库接口,避免破坏二进制兼容性
- 通过版本控制清楚地传达二进制兼容性中断
MiMa - 检查与以前库版本的二进制兼容性
MiMa 是一个用于诊断不同库版本之间二进制不兼容性的工具。
它的工作原理是比较两个提供的 JAR 的类文件,并报告发现的任何二进制不兼容性。通过交换 JAR 的输入顺序,可以检测到向后和向前的二进制不兼容性。
通过将 MiMa 的 sbt 插件 纳入您的 sbt 构建,您可以轻松检查是否意外引入了二进制不兼容更改。有关如何使用 sbt 插件的详细说明可以在链接中找到。
我们强烈建议每个库作者将 MiMa 纳入其持续集成和发布工作流。
由于隐式和命名参数等语言特性,使用 Scala 检测向后源兼容性很困难。检查向后源兼容性的最佳近似方法是同时运行正向和反向二进制兼容性检查,因为这可以检测出大多数源不兼容更改的情况。例如,添加/删除公共类成员是一种源不兼容更改,并且将通过正向 + 反向二进制兼容性检查来捕获。
在不破坏二进制兼容性的情况下演进代码
通过谨慎使用某些 Scala 特性以及在修改代码时可以应用的一些技术,通常可以避免二进制兼容性中断。
例如,使用这些语言特性是库版本中二进制兼容性中断的常见来源
- 方法或类的默认参数值
- 案例类
您可以在 二进制兼容性代码示例和说明 中找到详细的说明、可运行的示例和维护二进制兼容性的提示。
再次,我们建议使用 MiMa 来仔细检查在进行更改后是否破坏了二进制兼容性。
以向后兼容的方式更改案例类定义
有时,需要更改案例类的定义(添加和/或删除字段),同时仍然与案例类的现有用法保持向后兼容,即不破坏所谓的二进制兼容性。您应该问自己的第一个问题是“您是否需要一个案例类?”(与常规类相反,常规类可以更轻松地以二进制兼容的方式演进)。使用案例类的充分理由是当您需要结构化实现 equals 和 hashCode 时。
要实现这一点,请遵循此模式
- 使主构造函数变为私有(这也使类的
copy方法变为私有) - 在伴随对象中定义一个私有
unapply函数(请注意,通过这样做,案例类失去了在匹配表达式中用作提取器的能力) - 对于所有字段,在案例类上定义
withXXX方法,该方法创建一个新实例,其中相应字段已更改(您可以使用私有copy方法来实现它们) - 通过在伴生对象中定义一个
apply方法来创建一个公共构造函数(它可以使用私有构造函数) - 在 Scala 2 中,你必须添加编译器选项
-Xsource:3
示例
// Mark the primary constructor as private
case class Person private (name: String, age: Int) {
// Create withXxx methods for every field, implemented by using the (private) copy method
def withName(name: String): Person = copy(name = name)
def withAge(age: Int): Person = copy(age = age)
}
object Person {
// Create a public constructor (which uses the private primary constructor)
def apply(name: String, age: Int) = new Person(name, age)
// Make the extractor private
private def unapply(p: Person): Some[Person] = Some(p)
}
// Mark the primary constructor as private
case class Person private (name: String, age: Int):
// Create withXxx methods for every field, implemented by using the (private) copy method
def withName(name: String): Person = copy(name = name)
def withAge(age: Int): Person = copy(age = age)
object Person:
// Create a public constructor (which uses the private primary constructor)
def apply(name: String, age: Int): Person = new Person(name, age)
// Make the extractor private
private def unapply(p: Person) = p
此类可以在库中发布并按如下方式使用
// Create a new instance
val alice = Person("Alice", 42)
// Transform an instance
println(alice.withAge(alice.age + 1)) // Person(Alice, 43)
如果你尝试在匹配表达式中将 Person 用作提取器,它将失败,并显示类似于“无法将方法 unapply 作为 Person.type 的成员访问”的消息。相反,你可以将它用作类型化模式
alice match {
case person: Person => person.name
}
alice match
case person: Person => person.name
稍后,你可以修改原始 case 类定义,例如,添加一个可选的 address 字段。你
- 添加一个新字段
address和一个自定义的withAddress方法, - 更新伴生对象中的公共
apply方法以初始化所有字段, - 告诉 MiMa 忽略 类构造函数的更改。此步骤是必要的,因为 MiMa 尚未忽略私有类构造函数签名中的更改(请参见 #738)。
case class Person private (name: String, age: Int, address: Option[String]) {
...
def withAddress(address: Option[String]) = copy(address = address)
}
object Person {
// Update the public constructor to also initialize the address field
def apply(name: String, age: Int): Person = new Person(name, age, None)
}
case class Person private (name: String, age: Int, address: Option[String]):
...
def withAddress(address: Option[String]) = copy(address = address)
object Person:
// Update the public constructor to also initialize the address field
def apply(name: String, age: Int): Person = new Person(name, age, None)
并在你的构建定义中
import com.typesafe.tools.mima.core._
mimaBinaryIssueFilters += ProblemFilters.exclude[DirectMissingMethodProblem]("Person.this")
否则,MiMa 将失败,并显示类似于“类 Person 中的方法 this(java.lang.String,Int)Unit 在当前版本中没有对应项”的错误。
请注意,一种替代解决方案是添加回先前的构造函数签名作为辅助构造函数,而不是添加 MiMa 排除筛选器
case class Person private (name: String, age: Int, address: Option[String]): ... // Add back the former primary constructor signature private[Person] def this(name: String, age: Int) = this(name, age, None)
原始用户可以使用 case 类 Person,就像以前一样,在此更改之后,所有以前存在的方法都保持不变,因此与现有用法保持兼容性。
新字段 address 可以按如下方式使用
// The public constructor sets the address to None by default.
// To set the address, we call withAddress:
val bob = Person("Bob", 21).withAddress(Some("Atlantic ocean"))
println(bob.address)
不遵循此模式的常规 case 类将破坏其用法,因为添加新字段会更改某些方法(其他人可以使用这些方法),例如 copy 或构造函数本身。
此外,你还可以添加伴生对象中 apply 方法的重载,以便在一次调用中初始化更多字段。在我们的示例中,我们可以添加一个重载,该重载还初始化 address 字段
object Person {
// Original public constructor
def apply(name: String, age: Int): Person = new Person(name, age, None)
// Additional constructor that also sets the address
def apply(name: String, age: Int, address: String): Person =
new Person(name, age, Some(address))
}
object Person:
// Original public constructor
def apply(name: String, age: Int): Person = new Person(name, age, None)
// Additional constructor that also sets the address
def apply(name: String, age: Int, address: String): Person =
new Person(name, age, Some(address))
版本控制方案 - 传达兼容性中断
库作者使用版本控制方案来向用户传达库版本之间的兼容性保证。诸如 语义化版本控制 (SemVer) 等版本控制方案允许用户轻松地推理更新库的影响,而无需阅读详细的版本说明。
在以下部分中,我们将概述基于语义化版本控制的版本控制方案,我们强烈建议你将其用于你的库。下面列出的规则是除了语义化版本控制 v2.0.0 之外的。
推荐的版本控制方案
给定版本号 MAJOR.MINOR.PATCH,你必须增加
- 如果向后二进制兼容性中断,则增加 MAJOR 版本,
- 如果向后源兼容性中断,则增加 MINOR 版本,并且
- PATCH 版本表示既没有二进制也不兼容源。
根据 SemVer,补丁版本应仅包含修复不正确行为的错误修复,因此方法/类中的主要行为更改应导致次要版本升级。
- 当主版本为
0时,次要版本升级可能包含源和二进制中断。
一些示例
v1.0.0 -> v2.0.0是 二进制不兼容。最终用户和库维护者需要更新其所有依赖关系图,以删除对v1.0.0的所有依赖关系。v1.0.0 -> v1.1.0是 二进制兼容。类路径可以安全地包含v1.0.0和v1.1.0。最终用户可能需要修复引入的次要源中断更改v1.0.0 -> v1.0.1是 源和二进制兼容。这是一个安全的升级,不会引入二进制或源不兼容性。v0.4.0 -> v0.5.0是 二进制不兼容。最终用户和库维护者需要更新其所有依赖关系图,以删除对v0.4.0的所有依赖关系。v0.4.0 -> v0.4.1是 二进制兼容。类路径可以安全地同时包含v0.4.0和v0.4.1。最终用户可能需要修复引入的次要源代码中断更改
Scala 生态系统中的许多库都采用了此版本控制方案。一些示例为 Akka、Cats 和 Scala.js。
结论
为什么二进制兼容性如此重要,以至于我们建议使用主版本号来跟踪它?
从我们上面的 示例 中,我们学到了两个重要的教训
- 二进制不兼容版本通常会导致依赖关系混乱,使用户无法在不中断其应用程序的情况下更新任何库。
- 如果新库版本是二进制兼容但源代码不兼容,则用户可以修复编译错误,并且其应用程序应该可以正常工作。
因此,如果可能,应避免二进制不兼容版本,并在发生时明确记录,保证使用主版本号。然后,库的用户可以享受简单的版本升级,并在由于二进制不兼容版本而需要在依赖关系树中对齐库版本时收到明确的警告。
如果我们遵循本指南中列出的所有建议,我们作为一个社区可以减少理清依赖关系混乱的时间,并有更多时间构建酷炫的东西!